DeepSeek-V3 Technical Report
算法优化
架构
DeepSeek-V3 的模型架构沿用 DeepSeek-V2 如下图,主要引入了 2 个比较大的修改, 为了压缩 kv-cache 的空间修改了 attention 层,沿用 MoE 架构修改了 FFN 层。

Multi-Head Latent Attention (MLA)
这部分修改主要是用来压缩 kv-cache 的大小。思路很简单(但是人家敢搞),传统多头注意力机制 (MHA),对于输入的每一个 token 都需要存放他们计算后的 kv 值。GQA 和 MQA 减少了 kv-cache 大小,但是性能不行。所以 DeepSeek 提出了一种新的压缩方法:
-
训练一个矩阵 代表压缩矩阵,直接将输入 的 kv-cache 压缩为 ,这里压缩后的维度远小于隐藏层维度。
-
再训练 k 和 v 的解压缩矩阵 和 来将压缩后的 的维度还原为原始 k 和 v 的维度。由于原始 attention 机制里面引入了 RoPE 位置编码,而原始计算中这个位置编码是在计算完 之后做的加操作(也即是位置编码是嵌入到 中的)。这里解压缩之后带入不了位置编码信息了(没法直接在接压缩矩阵带入,会影响 V 矩阵;要么就重算全部 k 的位置编码)。
-
为了解决位置编码问题,同时也降低训练的内存开销,在计算 q 的时候也用同样的方法,训练一个压缩矩阵 和接压缩矩阵 ,然后采用解离 RoPE 的方式(Q带一部分位置信息,K 带一部分,两个做矩阵乘法就能把位置信息带入)。
-
具体思路,就是训练两个矩阵 和 来生成携带位置编码的矩阵,然后嵌入位置信息,拼在没有位置信息的 和 矩阵之后。这样在 可 做矩阵乘法就能把位置信息带入(这里配合架构图看)。
综上,每次存的时候只需要存压缩后的 kv-cache 和 的位置编码信息矩阵就好了,这些矩阵的维度比隐藏维度都要小得多。

DeepSeekMoE
参考模型架构图,DeepSeek 采用共享 个专家和路由到 个专家的模式。 具体公式如下:每个专家的输出做加。
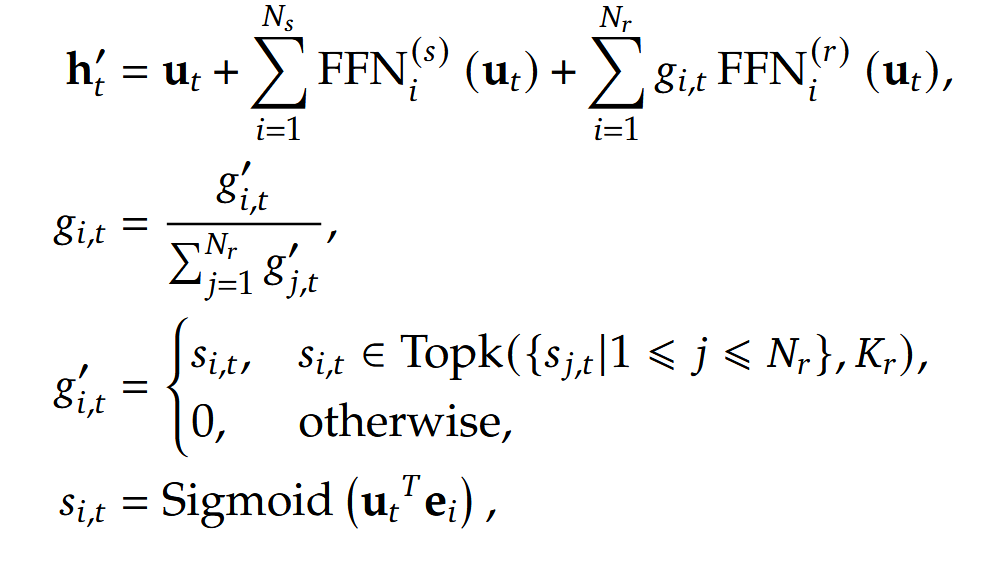
为了保证专家并行中的计算效率,专家负载要均衡(一个专家要是计算多了,需要等这个专家计算完成,存在一个同步点在这里,所以需要保证每个专家计算时间要一致,才能效率最大化)。他们提出的一个简单的不用 loss 的解决方法(他们认为添加一个额外的 loss 项,会影响模型训练的性能): 在门控输出每个专家得分时,加一个偏置 ,训练过程记录路由到专家的 token 数,多了就让偏置值衰减一个超参 ,如下:
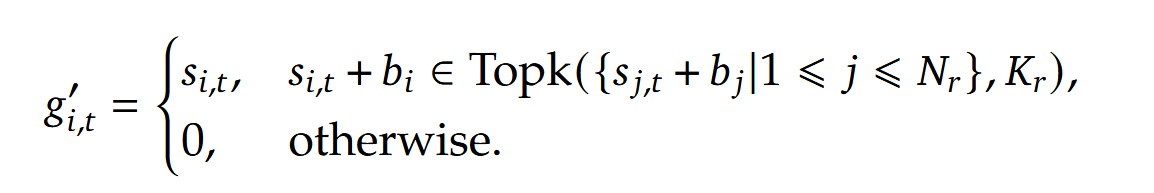
还提出使用一个 loss 来防止及其不平衡状况,如下(本质就是统计句子中每个 token 被路由到专家的分布,然后用这个 loss 保证平均):
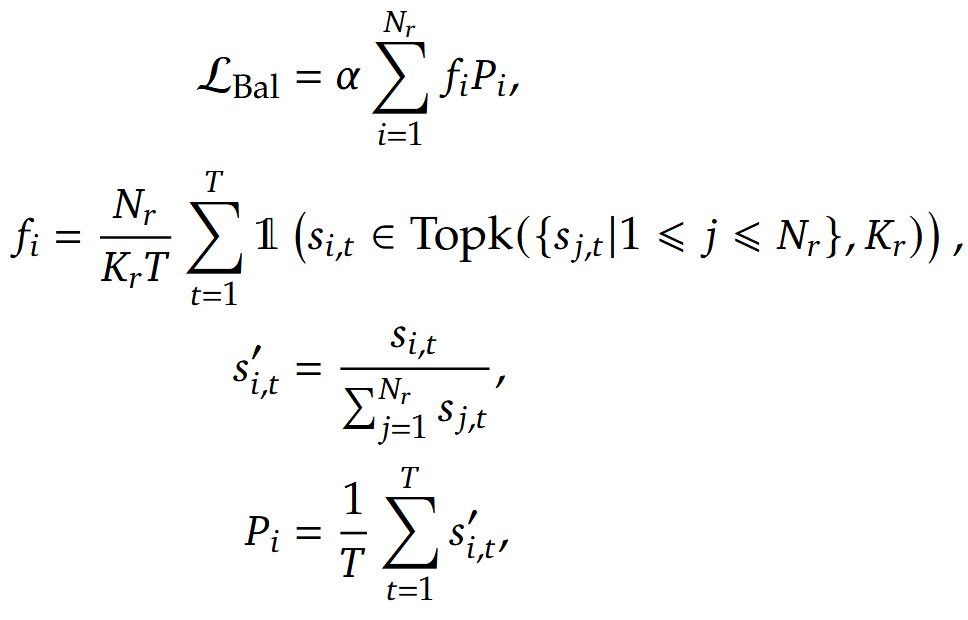
为了限制通信开销,他们还主张,每个 token 只能被发送到至多 M 个节点(这个需要看后面的工程优化,主要是为了 overlap IB 和 NVLink 的通信)。不同于其他 MoE 架构,他们不会丢掉 token。
Multi-Token Prediction (MTP)
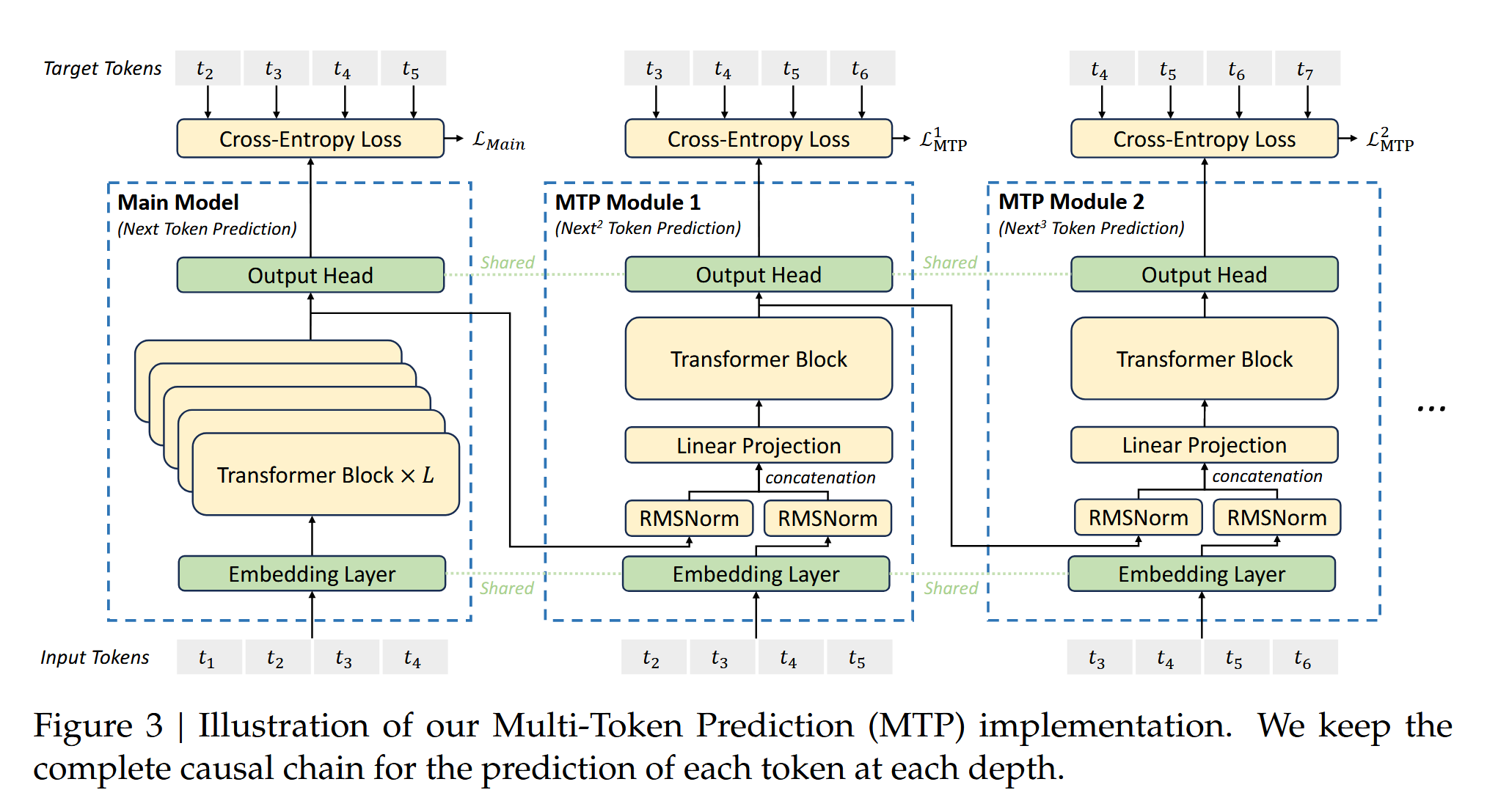
这一部分的优化也是很符合直觉的。直接看图,他们提出在训练中可以多预测几步,具体做法就是,多创建几个 MTP 模块(只在训练中存在),这些模块和主模块共享嵌入层和输出头。
每个 MTP 模块获取上一个模块的输出嵌入(预测嵌入),并和实际嵌入合并在一起,过一个线性投影。例如 MTP2 获取 MTP1 的输出也即是对 后 token 的预测,与实际值 后的嵌入合并在一起,过一个 Transformer Block 来预测 后的 token。
这一部分我感觉很符合直觉,因为人类思考过程也是这样的,会先蹦出来几个关键词,然后在思考中间怎么链接,获取扩散模型能符合这样的直觉。先用 Main Model 去生成,然后逐步扩散。
工程优化
训练优化
他们在训练中使用了 16-way 的流水线并行,64-way 的专家并行,和 ZeRO-1 优化的数据并行(2048张H800,256个节点,每个节点8卡,IB和NVLink都是满配置)。
相当于每 128 卡(16节点)组一个流水线的 stage,共 16 个 stage。专家并行和数据并行没看懂怎么去放的(��不同 stage 共享还是什么模式不清楚)。
流水线并行的优化技巧基本来源于 《Zero bubble pipeline parallelism》,《Chimera: efficiently training large-scale neural networks with bidirectional pipelines》这两篇文章,做了一个 DualPipe,见下图,两边同时进行前向传播。 那么在某一时间点(图中间部分)存在反向传播和前向传播同时进行的情况(前向和反向传播由于分属于不同 mini-batch 没有依赖所以可以同时进行)。

把这个过程放大(来源 Zero bubble 并行这篇文章的思路)来看,见下图,有许多可以 overlap 的机会。 MoE 架构模型的前向传播计算顺序为: ATTN -> DISPATCH(all-to-all通信) -> MLP(专家计算) -> COMBINE(all-to-all通信),反向传播就反着。 对于反向传播来说,需要计算两部分导数,权重和输入(或叫激活)。一般权重的导数只依赖梯度输入了,其他也不依赖它。
那么反向传播路径为(对照图):通信导数COMBINE(B) -> 求激活梯度MLP(B) -> 求权重梯度MLP(W) -> 通信导数DISPATCH(B) -> attention层导数ATTN(B)
接下来看如何重叠(这时候既有前向也有反向请求),这个图换下顺序好理解点,我们从 PP 紫色的开始,这个 PP 其实包含了两部分,前向和反向。前向结束时间点是 MLP 计算完,收集全部专家的结果,也即是 COMBINE(F) 完成,反向结束时间点是 ATTN 求导完,也即是 ATTN(B) 计算完成。
那么 PP 之后就是,接收到反向 COMBINE(B) 的通信请求,和前向 ATTN(F) 的计算请求,这两部分重叠。在 ATTN(F) 结束后的通信 DISPATCH(F) 和 COMBINE(B) 结束后的 MLP(B) 计算重叠。依次如图:

他们指出 NVLink 的速度是 IB 的 3.2 倍,以此来优化 all-to-all 通信,具体 all-to-all 通信是这样做的:
- 通过 IB 将数据发送到不同节点下和该 GPU 对于的节点
- 该 GPU 通过 NVLink 将 IB 数据转发到对应 GPU
- 目标 GPU 接收 NVLink 数据
由于 NVLink 速度是 IB 的 3.2 倍,意味着,每一个 IB 的传输可以和 3.2 个 NVLink 的传输并行(想像为流数据的传输过程,在处理上一个 NVLink 的传输,进行下一个 IB 的传输)。他们把一个 token 发送的节点数限制为至多 4 个节点,考虑节点内用 NVLink 是 IB 的 3.2 倍,那么一个 token 理论可以最大发给 13 个专家,能完全 overlap 这两者通信(实际是 8 个)。
为了实现上面这个功能,他们用了专门分配出来的 20SM,创了 10 个 communication channel 来搞(这几个 SM 单元只用来负责通信功能,没有通信的话空起来就比较浪费了)。
FP8训练
这一块主要提及如何进行低精度运算和保证精度不下降,如下图。
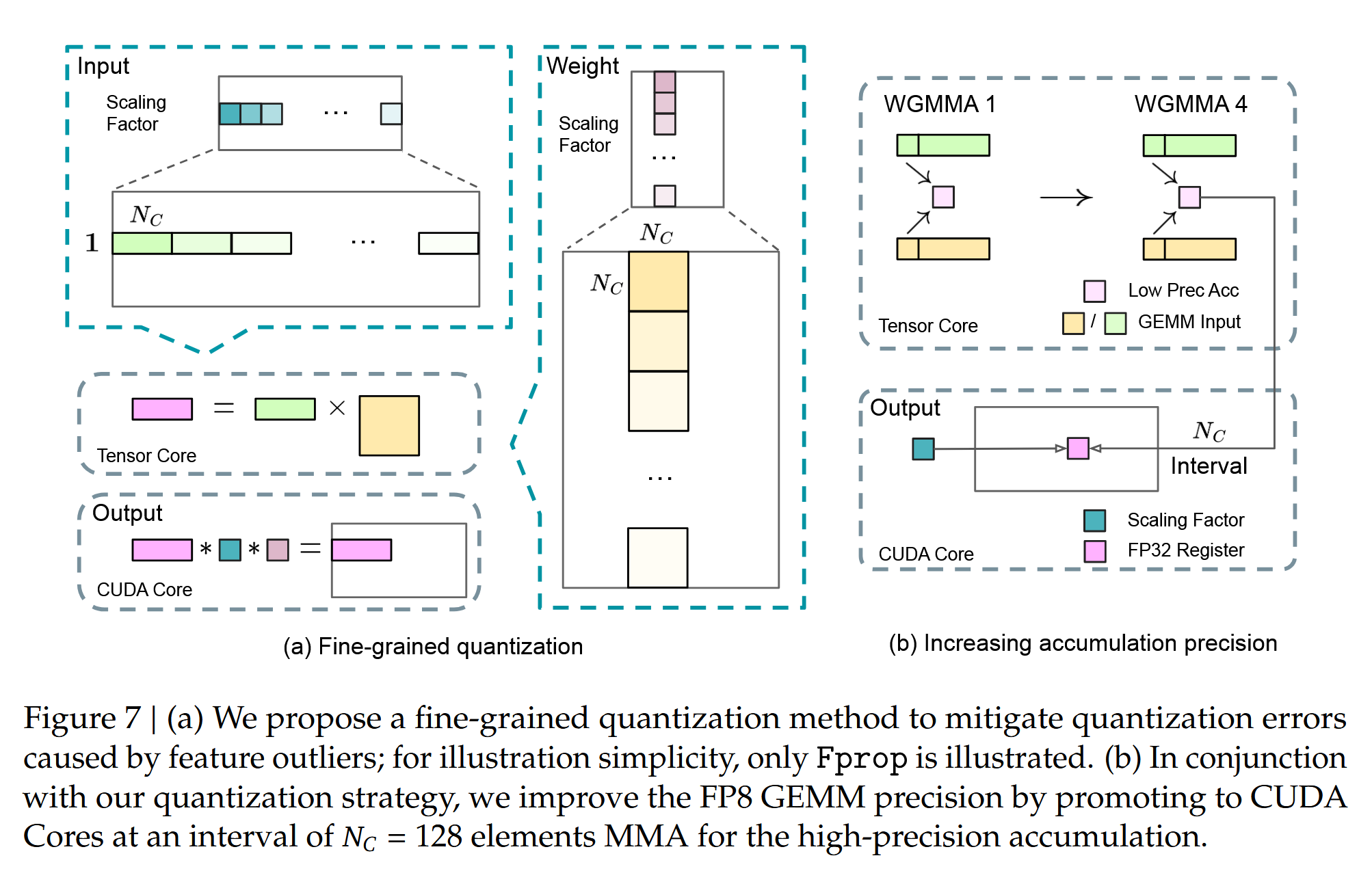
第一部分优化如左图,提出了两种缩放等级(像LLM.int8()这种是每一行维护一个缩放数来缩放数值到整数),而 DeepSeek 将 input 和 weight 按两种缩放等级,可以按行,或则部分行,或则块来缩放,这样能保证精度高。
第二部分优化如右图,提出在做矩阵乘法时,累加时由于精度低,用 Tensor 核累加后精度会下降。他们改了下算法在计算矩阵乘,在乘法算完后累加那里,把一部分累加值放到了 CUDA 核去继续�累加(用 FP32 高精度,这里还直接就去算缩放因子还原回去了)。这里还考虑到搬运过去的代价,也是用重叠,搬运和计算同时进行。
推理和部署
DeepSeek-V3 对 prefilling 和 decoding 两个阶段使用不同的并行策略,这一节的讨论不是太细节。
在 prefilling 和 decoding 的时候使用了专家冗余,也即是监控并共享经常访问的专家模型。和训练讨论啥不多,也用 overlap 策略。